神经网络发展简史
Neural Network Development History
McCulloch-Pitts神经元
The First Artificial Neuron
Warren McCulloch和Walter Pitts提出了第一个数学神经元模型,奠定了人工神经网络的理论基础。 这个简单的二进制阈值单元成为了所有后续神经网络发展的起点。
感知机诞生
Rosenblatt's Perceptron
Frank Rosenblatt发明了感知机,第一个可以学习的人工神经网络。虽然只能解决线性可分问题, 但它证明了机器学习的可能性,引发了第一次AI热潮。
反向传播算法
Backpropagation Algorithm
Geoffrey Hinton等人重新发现并推广了反向传播算法,解决了多层神经网络的训练问题。 这一突破使得深度学习成为可能,被誉为神经网络的"复兴"。
AlexNet突破
Deep Learning Revolution
Alex Krizhevsky的AlexNet在ImageNet竞赛中大获全胜,错误率从26.2%降至15.3%。 这一里程碑事件标志着深度学习革命的正式开始。
Transformer架构
Attention Is All You Need
Google团队提出Transformer架构,完全基于注意力机制,摒弃了循环和卷积结构。 这一创新为后来的BERT、GPT等大语言模型奠定了基础。
ChatGPT现象
Large Language Models Era
ChatGPT的发布引发了全球AI热潮,大语言模型展现出前所未有的通用智能能力。 标志着人工智能进入了一个全新的发展阶段。
模型架构演进
Architecture Evolution Timeline
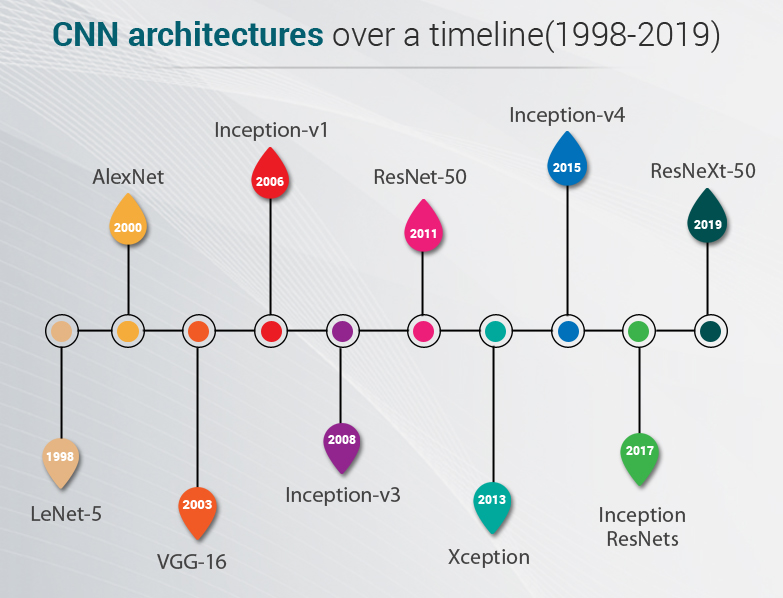
感知机
Perceptron
单层线性分类器
多层感知机
MLP
深度前馈网络
卷积神经网络
CNN
计算机视觉专家
Transformer
Attention
注意力机制革命
三大突破要素
Three Key Breakthrough Elements
大数据
Big Data
大规模标注数据集的出现为深度学习提供了充足的"燃料",使得复杂模型的训练成为可能。
GPU算力
GPU Computing
GPU的并行计算能力使得大规模神经网络的训练在时间和成本上都变得可行。
算法创新
Algorithm Innovation
关键算法的创新解决了深度网络训练中的核心问题,使得更深更复杂的网络成为可能。
经典模型详解
Classic Models Deep Dive
AlexNet
2012 · ImageNet Winner
核心创新
AlexNet的成功证明了深度学习在计算机视觉领域的巨大潜力。其创新性地使用ReLU激活函数、 Dropout正则化和数据增强技术,为后续CNN发展奠定了基础。
VGGNet
2014 · Visual Geometry Group
VGG证明了小卷积核和更深网络的有效性,其简洁优雅的设计理念影响了后续众多架构。
ResNet
2015 · Residual Networks
ResNet通过残差连接解决了深度网络的梯度消失问题,首次实现了超越人类的图像识别精度。
Transformer
2017 · Attention Is All You Need
革命性影响
Transformer彻底改变了NLP领域,其"注意力就是全部"的理念启发了BERT、GPT等 大语言模型的发展,成为现代AI的基石架构。
Attention Mechanism
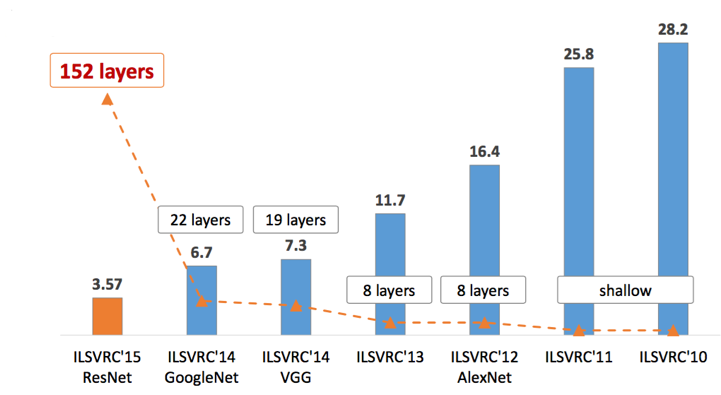
ImageNet竞赛历史
ImageNet Competition History
2010-2011
传统方法时代
基于手工特征的传统计算机视觉方法,错误率停留在25%以上。
2012
AlexNet突破
深度学习首次在ImageNet上取得突破性进展,错误率降至15.3%。
2015
超越人类
ResNet达到3.57%错误率,首次超越人类水平(约5%)。
迁移学习革命
Transfer Learning Revolution
预训练模型时代
Pre-trained Models Era
大规模预训练
在ImageNet等大数据集上训练通用特征
特定任务微调
在目标数据集上进行精细化调整
快速部署应用
大幅降低训练时间和数据需求
影响与意义
Impact and Significance
降低门槛
使得中小企业和个人开发者也能快速构建高质量的AI应用。
加速创新
从数月的训练时间缩短到数小时,极大加速了AI应用的开发周期。
知识复用
一个模型的学习成果可以应用到多个相关任务,提高了学习效率。
涌现能力现象
Emergent Abilities in Large Models
什么是涌现能力
涌现能力是指在大型语言模型中突然出现的、在较小模型中不存在的能力。 这些能力通常在模型规模、计算能力和训练数据达到某个临界点时突然显现。
关键特征
突然性
能力在达到临界规模时突然出现,而非渐进式改善。
不可预测性
很难预测何时何种能力会在模型中涌现。
规模依赖性
通常需要大规模模型才能观察到这些能力。
模型规模与能力关系
未来展望
Future Outlook
多模态AI
文本、图像、音频、视频的统一理解和生成,实现真正的多模态智能。
通用人工智能
向着更加通用、更加智能的AI系统发展,实现人类水平的认知能力。
高效计算
开发更加高效的模型架构和训练方法,降低计算成本和能耗。